

Designing a Patient Self-Reporting Stack Around Humans and AI¶
Every care team we talk to has the same complaint: patients happily text, leave voicemails, and fill out surveys, but those signals rarely make it into the plan of care.
Electronic records were never built to absorb that ambient context, and the people who could act on it are already drowning in portal messages and follow-up calls. Yet the value is obvious, timely symptom reporting keeps people out of the ED, surfaces social needs, and lets providers adjust therapy before a flare turns into a crisis.
What we need is a stack that captures self-reported data, triages it with large language models, and still gives clinicians the last word. The winning pattern blends thoughtful UX, observability, and a human-in-the-loop workflow.
This piece is co-written with my co-founder (CEO) and co-author, Dr. Christian Pean, a rockstar clinician and operator I’ve had so much fun building with at RevelAI Health.
Where Patient Self-Reporting Stands Today¶
- Remote symptom logging works when someone is watching. In the RELIEF pilot, oncology patients completed 80% of daily check-ins and nurses intervened on half of the triggered alerts, zero symptom-related ED visits during the study window (Curr Oncol, 2021).
- PROM and PGHD programs still stall in pilots. An umbrella review catalogued fractured adoption because implementation teams underinvested in workflow design, training, and staff capacity (Syst Rev Protocol, 2024).
- Integrating patient-generated data into the EHR is barely out of the lab. Only 19 studies met the bar in a 2019–2021 scoping review, most of them diabetes pilots that cited resource load and inconsistent review patterns as blockers (JAMIA, 2021).
- Portals add work faster than they add value. Cleveland Clinic primary care teams saw quarterly message volume double (340 → 695) and every 10 extra messages meant ~12 minutes more after-hours EHR time (J Gen Intern Med, 2024).
The signal is rich, but the stack is brittle. We ask patients to talk and then make it the nurse’s job to find needles in the haystack.
Why the Workflow Breaks¶
- Fragmented entry points: IVR trees, unsecured SMS threads, and chatbots all capture different slices of the story with no shared state.
- Review is entirely manual: care coordinators listen to voicemails, gather context from the chart, and often re-document the same complaint in yet another system.
- Outbound outreach is slow: when everything needs a human touch from scratch, patients feel ignored and high-acuity cases wait.
- No closed loop: patients don’t hear back quickly, so engagement drops; clinicians don’t trust the data, so they stop looking.
We can’t fix this by “adding AI” to a broken assembly line. We need to reframe the patient self-reporting stack as an orchestration problem.
Patterns for a Human-Centered Self-Reporting Stack¶
1. Intake that sets expectations up front¶
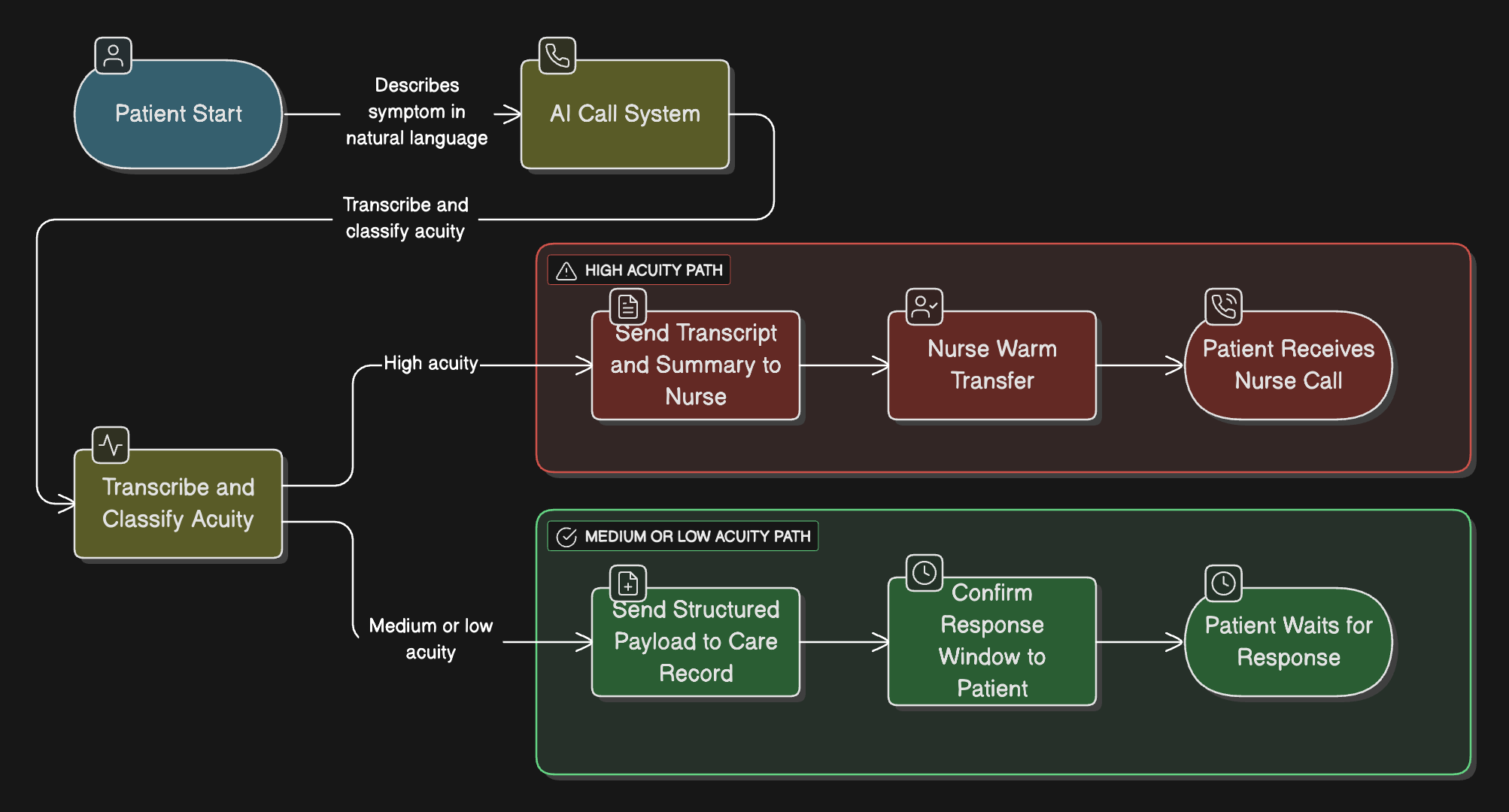
- Large language models can score acuity quickly (VUMC’s retrieval-augmented triage hit 0.98 sensitivity JAMIA, 2024).
- Patients hear a commitment (“a nurse will join in under a minute if needed” or “we’ll text you an answer in two hours”), which keeps engagement high.
2. Inbox triage that surfaces context, not noise¶
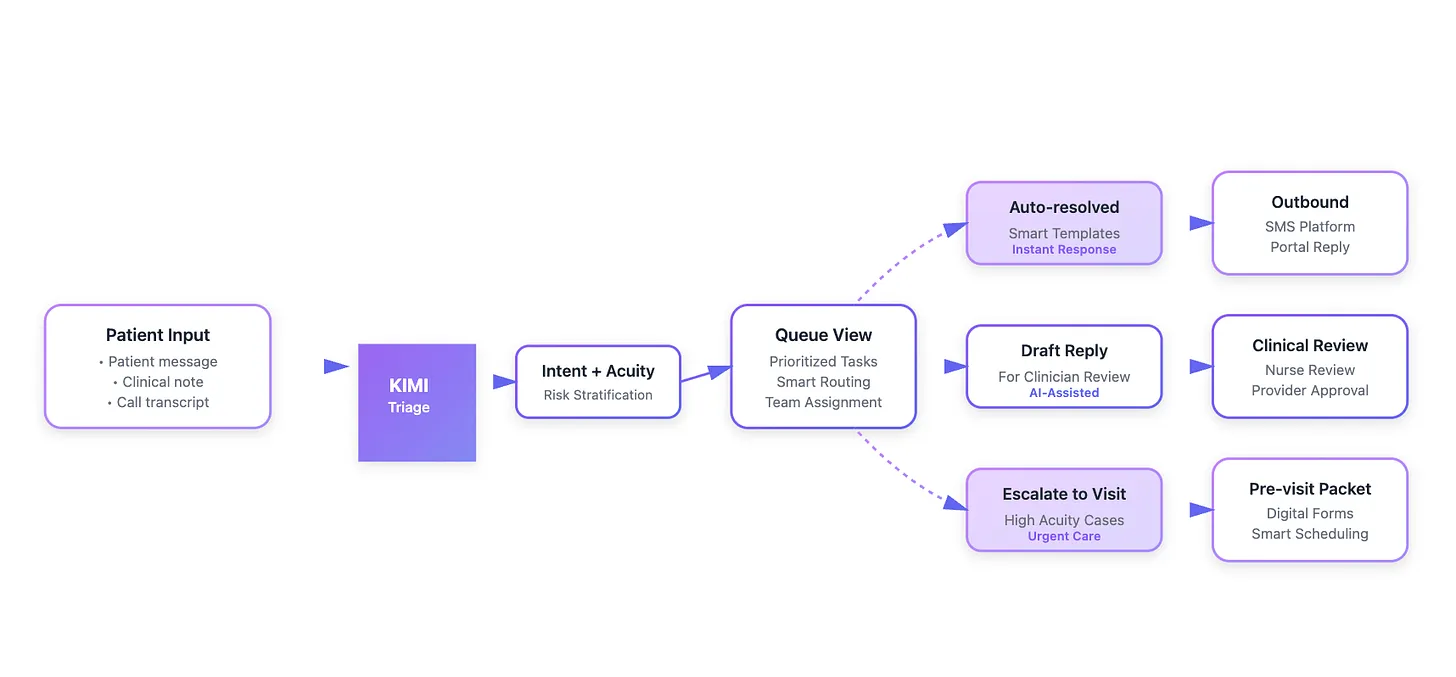
- Inbox views should group by intent (med refill, wound concern, paperwork) and stack related history—last summary, vitals, social determinants callouts.
- Drafting LLM replies isn’t about replacing clinicians; Mayo Clinic teams used AI drafts in ~20% of portal responses and reported lower task load afterward (JAMA Netw Open, 2024).
- Auto-resolution stays limited to low-acuity scripts (e.g., PT protocol reminders) and still leaves an audit trail.
3. Outbound nudges that feel bespoke¶
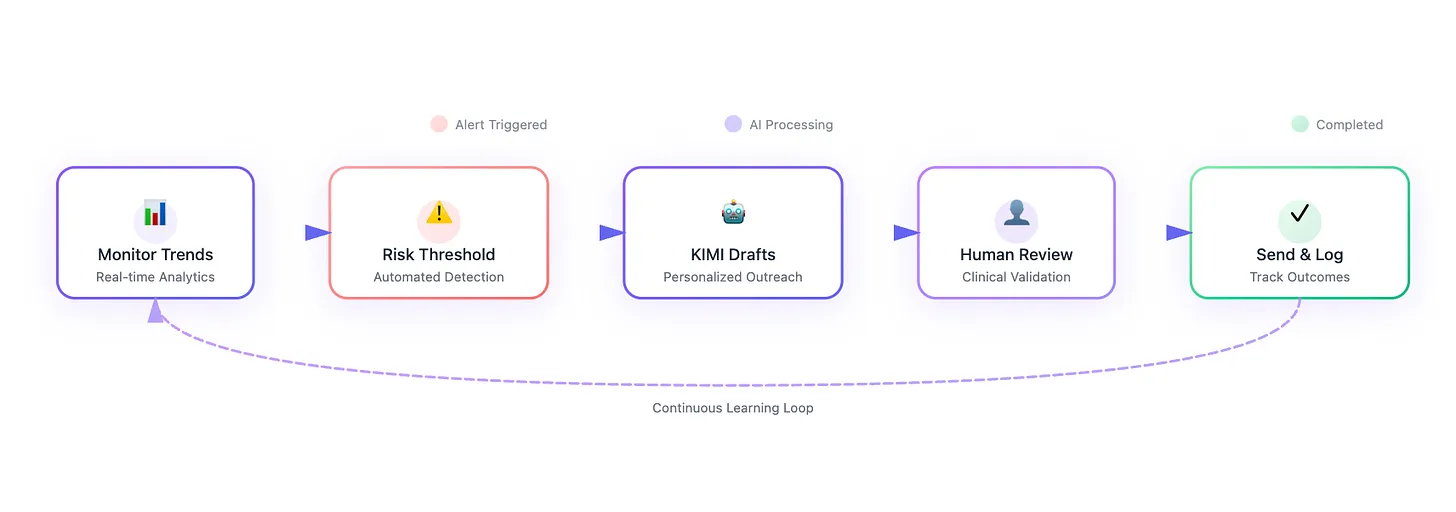
- Aggregated self-reports feed longitudinal trends (pain scores, medication adherence, social needs). When a metric drifts, the orchestrator drafts follow-up language tailored to that patient’s literacy and history.
- Humans confirm the plan, especially when it involves medication changes or complex counseling.
4. A shared workspace with observable loops¶
- Every automated action should show provenance: which notes were summarized, how the LLM scored acuity, and who signed off.
- Dashboards for clinical leaders track alert volume, average time to human response, and which prompts drive escalations.
- Patients see status indicators (“reviewed by triage nurse at 3:12 PM”), reinforcing trust that their data matters.
How LLMs Help, When They’re Tethered to Humans¶
LLMs earn their keep by shrinking the research burden on the care team:
- Context gathering: assemble medication history, recent labs, and prior outreach before a human opens the chart.
- Summarization loops: recursive summaries keep cross-channel interactions digestible without losing dosage details or timelines.
- Acuity classification: flag high-risk language inside texts and voicemails instantly, so humans act faster.
- Drafting outbound communication: suggest responses that a nurse can approve or tweak in seconds.
But they always operate inside a governed loop. High-acuity cases trigger synchronous handoffs. Every draft carries a “source disclosure” showing the snippets the model used. Clinicians can thumbs-up or correct the draft, feeding evaluation back into the system.
Translating Agentic Workflows to Care Transformation¶
In value‑based contracts, the early post‑discharge window concentrates avoidable utilization. A conversation‑first engagement layer turns those patient signals into Transitional Care Management that actually happens: the agent confirms discharge in plain language, reconciles medications from chart context, books the 7–14‑day visit in the same thread, and routes any red‑flag phrases to a human within minutes. The same playbook helps pre‑op. If a joint‑replacement patient repeatedly skips readiness assessments or leaves a distressed voicemail, the system tags “early‑intervention,” prompts a navigator call that solves transportation or medication confusion, and swaps in a tele‑visit when needed. These are the touches that move outcomes; among Medicare beneficiaries, receipt of TCM is associated with lower short‑term costs and mortality.
PROMs and patient‑generated data work best when missingness is treated as a clinical signal. The agent makes completion feel human—“Would you rather text or talk? It takes two minutes”—then, after two missed pings, automatically buckets the patient for navigator outreach. From there, campaigns are concrete: close missed follow‑ups, establish primary care, schedule the Annual Wellness Visit, and line up preventive screenings; for ED diversion, concerning symptom language triggers same‑day coaching and an urgent clinic slot. Boards can read this on one page: completion rates, time‑to‑first human touch after a concerning signal, and gap‑closure by segment. Randomized trials show that systematic electronic symptom monitoring improves quality of life and reduces unplanned use when tied to real‑time follow‑up—the exact loop this design operationalizes. (Steinbeck et al.)
What We’re Building at RevelAI Health¶
At RevelAI Health, we are stitching these patterns together so health systems don’t have to bolt on yet another point solution. Our orchestration layer listens to phone triage, portal inboxes, and AI-assisted callers, runs LLM-based acuity and intent models, and hands the care team a structured summary with suggested actions. Humans always close the loop, but they start from a prepared canvas instead of a blank screen.
The payoff is simple: patients know someone is listening, care teams spend time on judgment calls instead of transcription, and leaders can finally measure whether self-reporting is reducing avoidable visits.
Incumbent EHR vendors Epic, Cerner, the rest of the club certainly have the data gravity to tackle this, and they own the workflows inside the chart. But their strength on in-visit documentation hasn’t translated into nimble inbound and outbound engagement. Telephony integrations remain bolt-ons, multi-channel intent routing is brittle, and most of the tooling still assumes a human will manually stitch the story together.
We’re still refining evaluation datasets, UI treatments, and human review workflows—but the stack is finally showing that AI and thoughtful UX can make patient self-reporting actionable without losing the heart of human-centered care.
If you’re experimenting with your own self-reporting stack, I’d love to compare notes. The work ahead is making these loops tight, auditable, and empathetic.
Subscribe
Honest takes on AI, startups, and digital health—delivered to your inbox.
Your privacy is paramount. Expect content once or twice a month. Unsubscribe anytime if you don't like it.
Get Email Updates