
Can we reverse the curse of rigid journeys & workflows with LLMs?¶
Healthcare is littered with brittle decision-trees. Pre-op instructions, chronic-care check-ins, discharge follow-ups—each new edge-case multiplies the branches. Most workflows we have are cron-based, running at specific times and are very hard to personalize around patient needs.
Note
Let's build on an idea. No more endless if/then/else trees—just agents that watch, learn, and nudge exactly when it matters in healthcare.
Below I sketch a different approach inspired by DeepMind's "Era of Experience" paper: treat patient journeys as living agents that observe real-time data, reason over it, and choose the next best action—without needing humans to hand-craft every path.
A concrete example¶
Let's take an example of pre-appointment workflow for provider, (click to zoom the image):
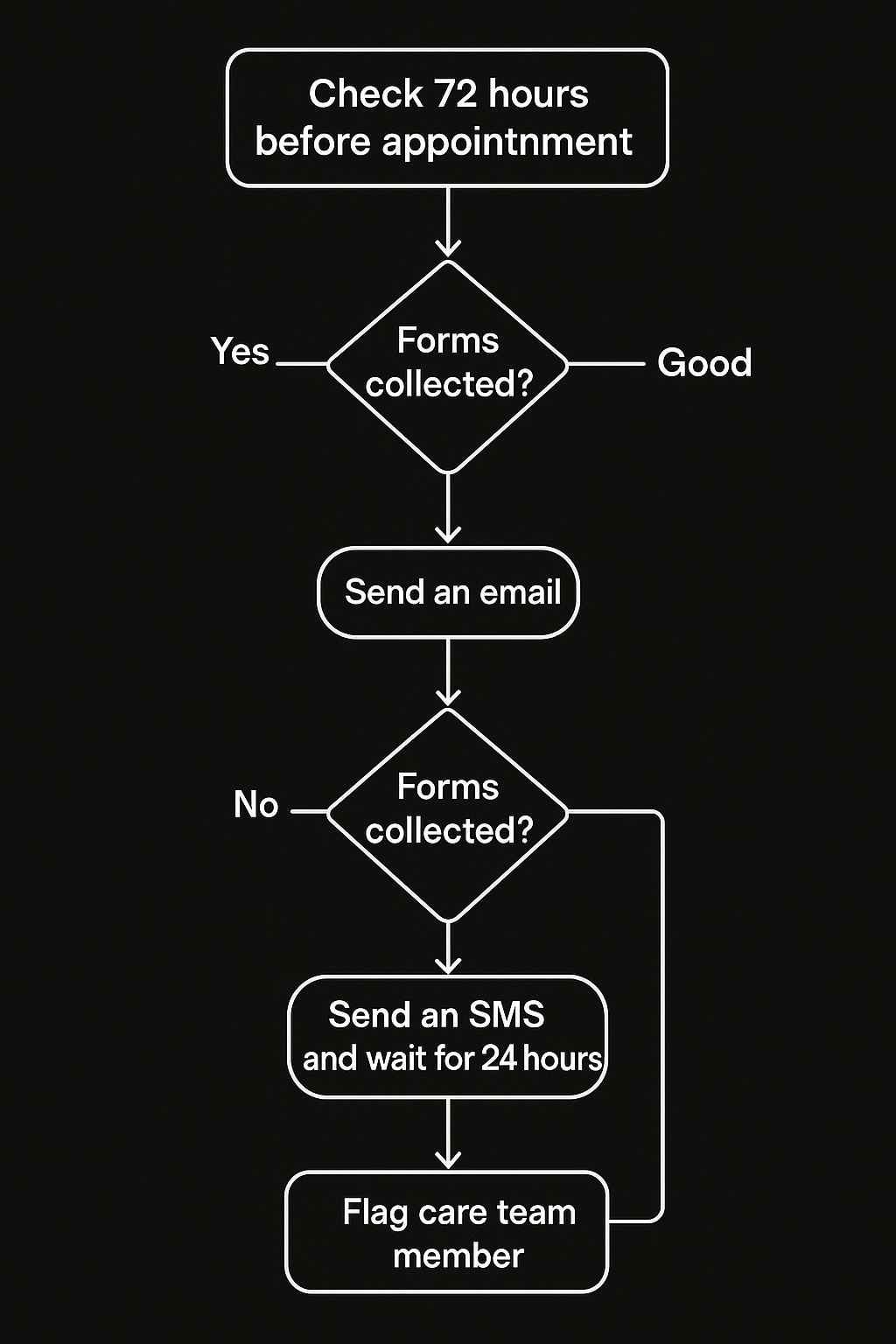
Looks sane—until you handle language preferences, missing lab-work, travel distance... you get the point. You'll be back to spaghetti code, and handling every edge case becomes difficult, not to mention dealing with diverse data makes it worse.
Enter the Era of Experience¶
Silver & Sutton argue we're moving from imitating past data to learning from live experience:
- Streams of Experience: Agents maintain persistent internal state across months or years (e.g., a wellness coach monitoring wearables)
- Autonomous Actions & Observations: Instead of reactive agents where you chat and get a reply, agents can execute actions like sending reminders to patients or flagging issues for doctors
- Grounded Rewards: Measuring environment-driven signals like biomarker data, heart rate, PHQ9 scores, or FHIR observation resources
- Beyond Human Level Reasoning: Language is universal but inefficient; experiential agents can invent non-linguistic internal codes and couple them to learned world-models for planning
I want these four pillars baked into patient journeys.
An observer-based paradigm for patient experience personalization¶
- Agents maintain streams of experience by observing EHR data, wearables, and internal application data
- Using an observer pattern where agents process incoming data
- Based on observations, agents use a broad set of policies and rules to carry out actions
- We can feed in FHIR APIs, event-based data, monitor data for an agent to observe
- As context windows improve, agents can build upon previous learning while incorporating new information
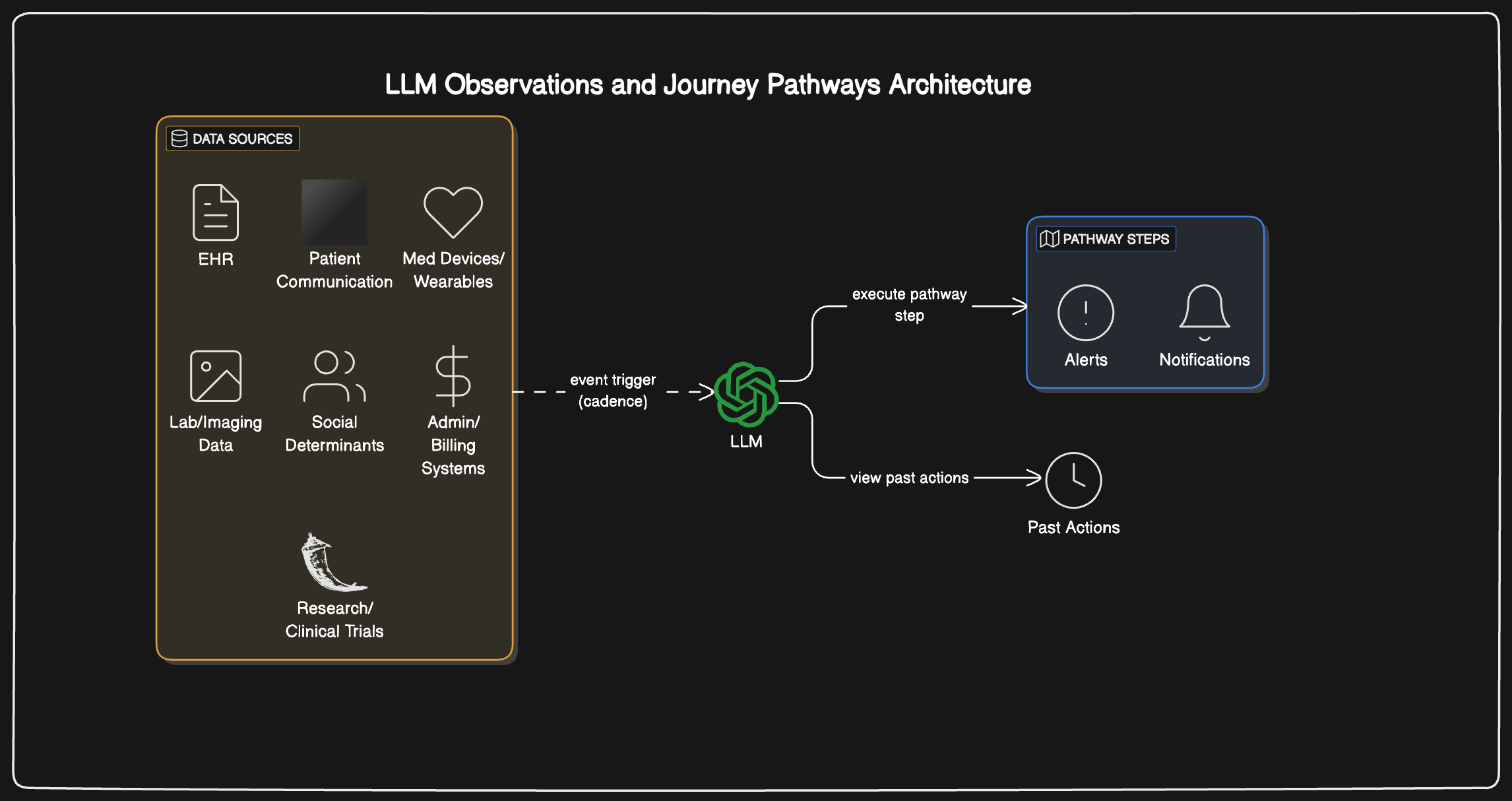
Agents carry out actions while being aware of their past actions, which also become observable data.
Optimizing for the rewards¶
These policies and journeys are built by subject matter experts like clinicians and researchers based on consensus about how to observe patient state and implement automation.
Sketching the code examples¶
w = Workflow(
policy="""
You're a virtual MA. Optimize for surgery readiness while minimizing alert fatigue.
{add_rules}
{policies_from_subject_matter_experts}
""",
actions=[
"action.send_sms",
"action.order_covid_test",
"action.notify_care_team",
"action.notify_primary_care_physician",
"action.<concrete_action_or_tool_name>"
],
recent_past_actions="""
{recent_past_actions_taken}
""",
store=PostgresStore(),
)
w.add_event({"type": "observation", "kg": 102, "ts": "2025-05-04T09:00Z"})
w.add_event({"type": "appointment_booked", ... })
## more events for realtime API
for action in w.decide():
execute(action)
LLMs can summarize past actions, and as context windows grow, they can take data in any format or store it long-term.
We can also use another LLM as a policy judge:
for action in w.decide():
llm_as_policy_judge_decision = llm_as_policy_judge.evaluate(action)
if llm_as_policy_judge_decision == "yes":
execute(action)
Or to mitigate risks, LLMs could predict the severity of actions and bring in human oversight when needed:
for action in w.decide():
llm_as_policy_judge_predicted_acuity = llm_as_policy_judge.acuity(action)
if llm_as_policy_judge_predicted_acuity in ["high", "medium"]:
care_team_decision = flag_care_team(action)
if care_team_decision == "yes":
execute(action)
Upsides of this approach¶
- Scales to thousands of edge-cases without exploding DAGs
- Handles messy data LLMs can understand HL7, FHIR, wearable APIs and unstructured notes etc..
- Enables culturally-relevant comms (tone, language, reading level) on the fly
Downsides¶
- Deterministic, auditable flows become stochastic—regulators will ask "why?"
- Reward hacking is real: bad metrics → spam or worse
- Streaming RL + HIPAA-grade logging is early days
Mitigating the risks¶
- Policies and rewards must be well-defined
- Reasoning models need to predict severity accurately. For high-acuity actions like medication recommendations, care-team members must be involved. o3 model is already showing positive signs.
- Subject matter experts need to craft clear policies on what AI handles vs. what requires human intervention
- Extensive simulations and test scenarios are needed to validate the approach
My hope and conclusion¶
Rigid pathways got us this far, but they break under real-world complexity. By letting agents experience patients' lived data—and grounding them in clinical rewards—we can deliver care that adapts like a good nurse: quietly watching, acting only when helpful.
Making this vision reality requires three things: well-crafted AI policies that encode clinical wisdom, a willingness to experiment in safe but meaningful ways, and subject matter experts collaborating across disciplines. The technology exists—what's needed now is the courage to reimagine workflows from first principles.
At RevelAI Health, we're bringing this approach to life in the MSK space. Our platform orchestrates pre-op and post-op journeys, unifies fragmented communications, and applies generative AI to handle complex operative workflows. We're seeing early validation that intelligent agents can dramatically reduce the friction patients experience while giving time back to care teams.
Interested in joining us on this journey? We're hiring our founding engineer to help shape how AI transforms healthcare workflows from rigid decision trees to living, adaptive experiences.
Subscribe
Honest takes on AI, startups, and digital health—delivered to your inbox.
Your privacy is paramount. Expect content once or twice a month. Unsubscribe anytime if you don't like it.
Get Email Updates