
Navigating the AI Hype and Thinking about Niche LLM Applications¶
Recently, there has been a surge of enthusiasm surrounding large language models (LLMs) and generative AI, and justifiably so: LLMs have the power to revolutionize entire industries. Yet, this enthusiasm often gives rise to inevitable hype. It appears somewhat counterintuitive to avoid incorporating “AI” into a product’s presentation, considering the immediate market interest it can generate.
It’s funny how we sometimes get caught up in the thrill of flashy new tools, losing sight of what really matters — solving actual problems.
In this article, I’m not discussing ChatGPT prompts that promise to transform you into a 10X person, grant you a competitive edge, or make you fear being replaced by AI aficionados at work. However, I do recommend learning prompting techniques.
For example, check out this excellent free course on prompt engineering by Andrew Ng or dive into intriguing papers like this one to discover effective prompting patterns and always there is enough about prompts on Twitter. Prompting is an excellent technique to get a lot out of LLMs.
We’ll delve into using LLMs for specialized tasks with enterprise or organizational private data, like question-answering, summarization, clustering, recommendations, and crafting conversational/neural search experiences.
I’ve decided to jot down what I’ve learned for myself and the team I work with, and I thought, why not share it through this article? In our upcoming posts, we’ll be chatting about topics like LLM Chains, Intent Recognition, adding task-specific tools, clustering, creating a recommendation system, fine-tuning open-source LLMs, and our way of testing the system, which we are continuously improving and learning from the research and open-source community. So, stick around, and let’s explore these ideas together!
Augmenting LLMs with private domain-specific data¶
LLMs, such as GPT, and other open-source LLMs, are exceptional technologies for knowledge generation and reasoning. Trained on extensive public data, these foundational models can be adapted for diverse tasks. Two common paradigms have emerged to tackle domain-specific problems and incorporate private/external knowledge:
- Fine-tuning a pre-trained model for domain-specific applications involves training the model on a particular dataset using hosted large language model APIs or open-source foundational models like Llama. This process incorporates existing foundational datasets and augments or aligns the model with domain-specific supervised or unsupervised data, depending on your use case. However, we won’t discuss this paradigm in the current article; I plan to write a separate piece on this topic.
It’s worth noting that this approach can be expensive, as fine-tuning typically requires training on costly GPUs if using an open-source model or utilizing high-priced Azure or OpenAI endpoints. Although emerging patterns like PEFT and LORA now enable training open-source LLMs on smaller GPUs, aligning models to specific domains such as healthcare or finance remains a challenge. This area necessitates extensive testing, and we’re still in the process of deepening our understanding. - The second emerging paradigm is a context-augmented generation or often mentioned as Retrieval Augmented Generation (RAG), wherein the relevant context is incorporated into the input prompt, leveraging the LLM’s reasoning capabilities to generate a response.
In this article, we will concentrate on this technique and explore methods for embedding domain-specific private data. Regardless if you take option 1, RAG still has its place because most of the LLMs are frozen at a certain point, where you still need RAG to connect to your LLM with ever-growing or fresh data-set through search, etc.
Retrieval Augmented Generation (RAG)¶
The concept is straightforward: use semantic search or other retrieval techniques to extract pertinent documents from your corpus, then feed the relevant text segments into the language model (LM) as prompts or contexts. This allows the LM to reason, answer questions, and generate specific, relevant content without deviating from unrelated topics. Careful prompt design and model temperature management help keep the LM focused.
This approach is highly effective for many basic applications, eliminating the need to fine-tune the LM or complicate the deployment process, as most of the current LMs are frozen and don’t have live data access. Connecting the LM to external data sources becomes a powerful tool for addressing various queries. Integrating the few-shot prompting technique with retrieved text segments can further enhance the model’s ability to generate accurate responses.
The retrieval process and corpus organization play crucial roles in this approach, as how documents are segmented, queried, and correlated significantly impacts the relevance of the content fed to the LM based on user queries. Document ranking processes also help ensure the most pertinent information is provided to the LM. Numerous open-source frameworks are available to facilitate these tasks.
To optimize results, it is essential to be pragmatic in selecting the appropriate techniques and understanding when and where to employ them. Additionally, considering your organization’s machine learning operations (MLOps) processes is crucial for seamless integration and deployment.
Embedding is a process of capturing the semantic meaning of the text into numerical vectors.
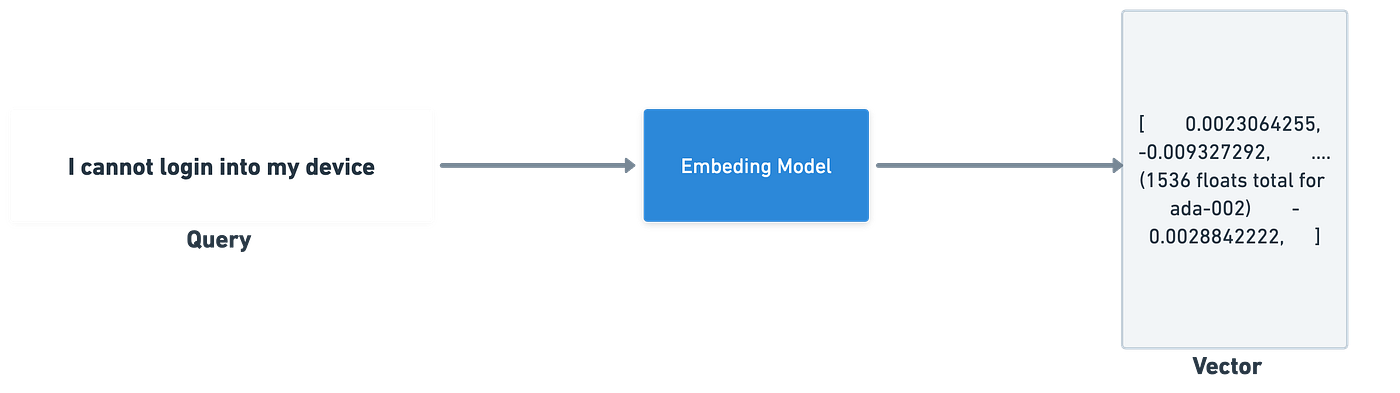
- In this process, embeddings are generated for search document segments and later fed into LLM. Embeddings transform the text into vector representations, situating them within a high-dimensional space. For those familiar with natural language processing (NLP) prior to the LLM era or before the advent of Google BERT, models such as Word2Vec and GLOVE may come to mind.
It is important to acknowledge the remarkable advancements made by the research community, OpenAI, Cohere, and others in refining embedding techniques and in making them more developer friendly or accessible. These embeddings can be stored in common vector stores, Redis, Postgres, Vector database, or in-memory NumPy arrays, to facilitate further analysis and manipulation. - User queries are similarly vectorized after converting relevant documents into vector representations and storing them in a vector store. To retrieve the most pertinent document segments based on the user’s query, a nearest neighbor search, often employing the k-NN algorithm, is performed within the vector space, usually using a Cosine similarity score or other distance calculation techniques.
This process ensures that the most closely related content is identified and retrieved in response to user inquiries. Furthermore, ranking or re-ranking based on relevance scores can be applied at this stage to enhance the accuracy of the results. - A comprehensible response is generated by feeding the top-K relevant segments to the language model (LM). The LM enhances the neural search process by reasoning from the provided document segments and the prompt for steerability of the response, ultimately producing a highly human-like response.
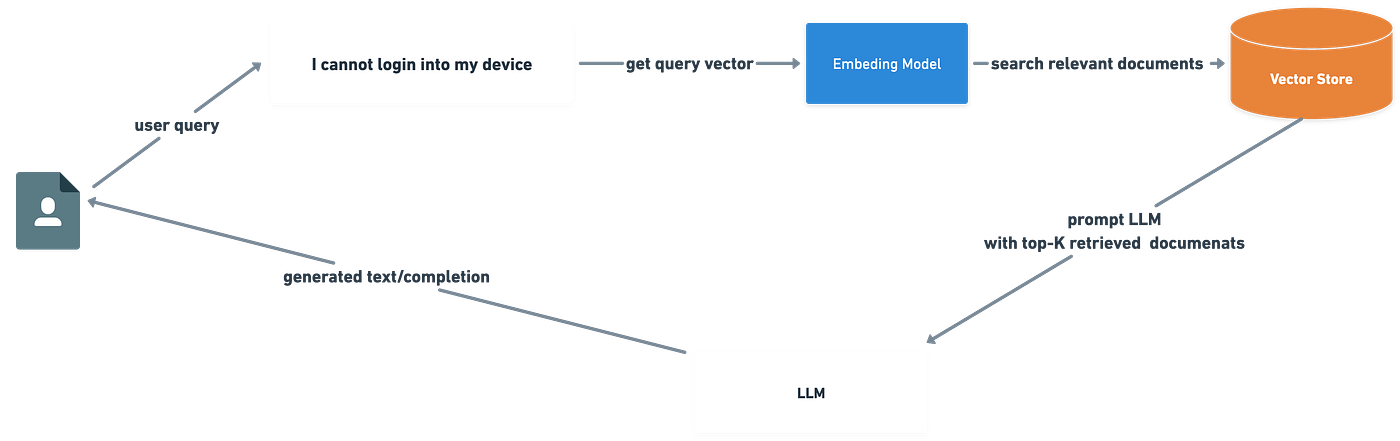
Data-preprocessing, chunking, and retrieval techniques¶
Data-preprocessing The nature of your data necessitates careful pre-processing to ensure optimal results. It’s essential to eliminate extraneous information, such as redundant headers and footers, HTML tags in HTML pages, PDFs, and other documents. Minimizing noise in the data can enhance the accuracy and relevance of query results more effectively. These fundamental data-preprocessing steps are not unique to this context; they are essential for constructing any efficient information retrieval system.
Chunking Chunking involves breaking down larger portions of documents into smaller text blocks, which is a crucial data-preprocessing step before creating a vector store from the corpus. This process is important for two main reasons:
- Optimizing the accuracy of user search results by removing noise from the corpus, converting them into smaller relevant chunks, and retaining only the most relevant text without losing context or essential meaning.
- Adhering to token limits imposed by embedding models and the constraints of the LLM’s context must be considered.
To determine the most effective chunking approach, you’ll need to experiment with various techniques that account for the nature of your data. Defining chunk size, chunk boundaries, and overlap is essential. Begin by analyzing the characteristics of your data and adjusting the techniques accordingly.
A note on pricing: When opting not to use an open-source, self-hosted embedding model, it’s crucial to be cognizant of the potential costs associated with proprietary models, such as those from OpenAI. Although the per-token cost might seem inconsequential (for instance, $0.004 per token), large datasets can add up to substantial expenses.
Let’s do some quick calculations to illustrate this point. Suppose you have 100,000 documents (PDFs, CSVs, etc.), each with an average of 70,000 tokens. It’s essential to thoroughly remove noise and strategically chunk data, or perhaps start small to manage costs. It’s vital to avoid the repetitive regeneration of embeddings due to minor oversights such as inefficient chunking, inadequate application of segment overlaps, or subpar data pre-processing. These seemingly small errors can quickly become expensive in time and resources. Also, here’s a rough estimate of the scenario discussed above:
(70,000 tokens/document * 100,000 documents) / 1000 * ($0.0004 per 1000 tokens for embeddings API) = $2,800 for using the embeddings API.
Here are a few techniques for chunking data effectively. Additionally, this article from Pinecone provides an excellent guide on implementing these chunking methods proficiently.
**Create segments of paragraphs/sentences ** The simplest method for dividing text into chunks is by using a fixed size, which can be based on the number of words or tokens. For example, in Python, you can perform a rudimentary text.split() operation to obtain words or sentences, create chunks based on word count up to a specified maximum, or use re.split(r’\n(?=[A-Z])’) to separate paragraphs. Count the words and create additional paragraphs as needed to ensure that paragraphs don’t exceed the maximum size. You can use Spacy or NLTK for sophisticated sentence segmentation instead of our naive regex or word split only. Alternatively, you can use token-based length calculations with a function like OpenAI’s tiktoken.
However, this approach may result in incomplete paragraphs or sentences, potentially losing context among the various segments ultimately stored in the database.
Overlapping segments To mitigate the issue of incomplete paragraphs or context loss among various document segments, we can employ a technique that generates overlapping segments. For instance, you could overlap at least five segments together. Utilizing the mentioned method, create segments and overlap a minimum of five paragraphs or segments into one chunk until the maximum size is reached. Repeat this process to cover overlapping content across the five segments.
While this approach helps preserve context among segments, it may also substantially increase costs, as more embeddings will be generated. But this approach does help to some context with the problem of losing the context among segments.
Choosing the right tools for storing and querying vectors The landscape of tools for vectors and vector databases has grown rapidly. The choice truly depends on which tool aligns best with your specific objectives. Key considerations include whether you require a self-hosted solution or a managed vector store. Additionally, if opting for a hosted solution, it’s crucial to check if it satisfies your compliance requirements, particularly if you’re operating in a heavily regulated environment like healthcare or fintech.
We’ve tried the following tools and vector databases:
- FAISS, as defined by Facebook, is an open-source library designed for efficient similarity search and clustering of dense vectors. It’s not a vector database, but it supports popular algorithms such as k-NN and nearest neighbor search. The API is user-friendly and straightforward. However, it’s important to note that you’ll need to host FAISS independently on a GPU or server yourself.
- Pinecone, fully managed vector database that has gained considerable popularity recently. It supports k-NN and other distance metrics such as cosine, dot product, and Euclidean distance, which are easily configurable via their user interface. Pinecone’s high availability is a strong selling point, but its metadata search functionality, which sets it apart from many other tools, is similar to MongoDB-style JSON queries.
This feature enables not only vector-based search but also filtering of metadata JSON, for example, by user ID or specific attributes. Currently, we’re uncertain about their support for compliance standards such as PCI-DSS and HIPAA. - Managed OpenSearch by AWS is another viable option that supports vector querying and popular algorithms like k-NN. OpenSearch could be an efficient alternative if you’re operating in a regulated environment and prefer not to manage FAISS GPU instances on your own.
The list of semantic search-based retrieval tools provided here is not exhaustive. I have shared it based on our experiences and the outcomes of our evaluations, providing insights into the tools we’ve tried and tested.
I’d also like to note that a semantic search-based retrieval system isn’t the only viable solution. k-NN might not be correct algorithm always, maybe all you need is approximate search a-NN. Depending on your needs, other methodologies may prove more effective. For instance, if your task involves comparing two documents or pieces of information, alternative strategies may be better suited.
Perhaps you’re looking to model a network or knowledge graph, or us a graph database such as Neo4J. Or, maybe your task involves querying a website for specific information. e.g DuckDuckGo library for search functionality or even a proprietary API returning JSON within your organization.
The key is to select the approach that best aligns with your specific objectives, and then feed the information to LLM for response generation and reasoning.
Zero-shot vs few shot prompting and steering LLMs¶
The primary distinction between zero-shot and few-shot learning lies in the approach to inference. In zero-shot learning, the language model is asked to complete a task without explicit examples, whereas, in few-shot learning, the model is provided with a limited number of examples, or “few-shots,” embedded within the prompt. Prompts are very important to steer the model in a direction and avoid hallucinations. Besides prompts, the temperature setting for the LLM also plays an important role.
Consider the following example: We have a QnA bot tasked to answer questions from the provided context retrieved using a vector store and user’s question query. We want the LLM to only answer based on the context.
prompt_prefix = '''
Answer only from the content that have been provided to you in the context,
other wise reply "I cannot answer". You are a QnA assistant
Context:
{retrieved_context_from_vector_store}
'''
Zero-shot prompting example combines with context as a prefix
In this example, we won’t give any explicit or prior examples of LLMs answering the question. Usually, you get good performance on zero-shot tasks as well unless you want LLM to answer questions in a particular manner
Few-shot prompting example combined with context as a prefix
If you aim to guide the model to respond in a specific format, employing few-shot prompting techniques could be beneficial. By providing a handful of examples demonstrating the desired response style. Remember, prompt crafting may require experimentation, and the optimal approach could vary depending on the particular Large Language Model (LLM) in use.
few_shot_prompting = prompt_prefix + '''
Question: Who was the president in 2015?
Answer: The name of the president is Barak Obama
Question: Tell me a joke
Answer: sorry this is something not mentioned in the context
Question: <some domain-specific-question>
Answer: <domain specific style of answering a question>
'''
A note on **tools and open-source frameworks**Tools like Langchain and llama-index are undoubtedly powerful, helping to reduce much of the labor involved in tasks like data loading, building indexes, and creating retrievers. They are good for getting started or for building personal projects.
Remember, the following is a very subjective experience and your mileage may vary.
From our perspective, using these libraries in production systems might not be the best fit. They tend to obscure the underlying workings through many abstractions, limit customization possibilities, complicate memory management and retrieval customization, and sometimes need to be revised to reason about. While working with LLMs is straightforward, we found creating a few Python classes to meet our objectives more practical rather than investing significant effort into mastering a new framework.
The open-source ecosystem, particularly that of Langchain, is truly impressive. It offers a wealth of innovative ideas from the community that are worth exploring and integrating into your own projects. Also, data loaders they offer are worth using because it’s a lot of investment to write data scrapers or loaders or already existing tools yourself. Do check out llama-hub or LangChain data loaders.
Also, do check out Cohere, or Sagemaker Jumpstart models. They both are great options to deploy models in your VPC if you work in a heavily regulated environment and want to use open-source LLM. We plan to do another article about how to deploy the model in a restricted environment and train it. If you want to use OpenAI models Microsoft Azure OpenAI as a service could also be a good option, although you will have to request access to it.
Using LLMs for recommendations and clustering tasks¶
LLMs can capture the semantic meaning of a text or any data type through embeddings or numerical vectors in high-dimensional spaces, enabling the correlation of data once embedded. As previously discussed, we'll apply a similar technique for embedding data to augment relevant response generation. Instead of generating responses, k-NN (nearest neighbours), a-NN, or any distance algorithms can be applied on vector stores, etc., such as clustering users based on similar actions, product preference, or any other correlations depending on your dataset and domain.
LLM-generated clusters can produce more accurate categories than rule-based systems and potentially address cold start problems. They can work with noisy un-labeled data sets, which can help us create collaborative filtering or content-based recommendation systems.
Deep learning-based recommendation systems, e.g., that embed user activity into vectors, have already been implemented at a petabyte of billions of actions scales by platforms like Pinterest and YouTube. However, it’s worth mentioning that embedding techniques have significantly improved over time, making it easier to capture semantic meaning in data, and with the advent of new vector query/storage tools, it has become easier to deploy a recommendation system compared to what it used to be five years ago.
This OpenAI Cookbook is an excellent resource to help you get started and understand the implementation process. To create embeddings, you don’t have to rely solely on OpenAI embeddings model. You can use any LLM, such as BERT or any open-source model, sentence transformer, etc., that effectively captures the semantic meaning of your data.
Following is the image generated using OpenAI cookbook mentioned above on this data set. However, these are high-dimensional embeddings, which are hard to visualize. They have used t-SNE to compress them into two-dimensional space to visualize the nearest neighbor recommender concept.
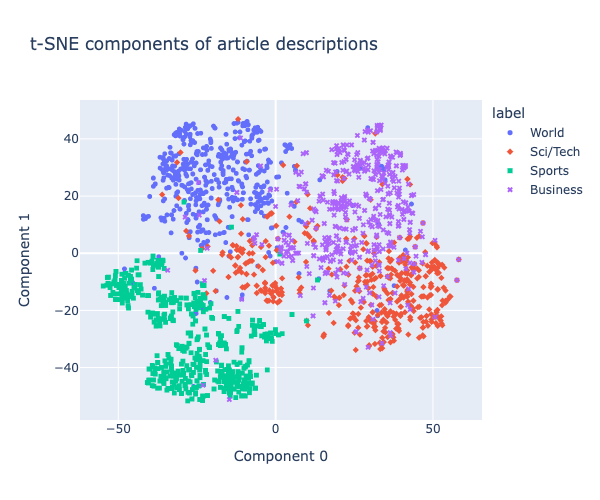
Article description clusters generated using OpenAI’s notebook
Having said all of the above, you may need to integrate your business logic and other rules to create an effective recommendation system to develop a production-grade system. It’s crucial to consider the diversity of the data and rigorously test the system using both online and offline evaluation metrics. Online testing may involve A/B testing tailored to your domain, while offline metrics include measuring precision, recall, F1 scores, and assessing the data’s diversity.
Thinking about collaborative filtering vs content-based models and modeling user sessions etc., do add more complexity, and it’s yet unclear how LLMs alone can solve that. Striking the right balance between these factors is essential for a successful recommendation system.
Improving search experiences within organizations¶
There’s not much more to add here, but it’s worth emphasizing that the above-mentioned embedding techniques, when paired with LLMs, can significantly enhance an organization’s search experience. Moreover, the RAG approach can enable a more descriptive and user-friendly presentation of search results.
If your interest goes beyond just LLMs, I’d recommend this fascinating read from Pinecone explaining how Spotify enhanced their podcast search experience. The concepts aren’t new here, but the barrier to entry for creating superior experiences with less engineering effort has markedly decreased, thanks to LLMs and the new embedding techniques they unlock.
Thinking about the niche applications all of the above unlocks¶
Identifying the precise potential of Large Language Models (LLMs) for a particular organization is difficult; it largely hinges on the unique datasets and the domain expertise for a niche. For instance, a healthcare specialist might find a distinct set of use cases for LLMs, whereas a professional in fintech could leverage the technology in an entirely disparate manner.
This broad applicability and adaptability is a key aspect that makes the LLM ecosystem so vibrant. For organizations with extensive data assets, the prospective advantages of deploying LLMs outweigh the associated risks, provided they are applied with caution and checks in place. We have previously discussed some use cases and their respective implementations.
In addition, here are a few more worthy of mention:
- QnA and customer service chatbots: I still remember the days of NLP pre-transformers, BERT or any LLM, using scikit-learn, Keras or sometimes Regex for intent recognition, using Spacy/duckling for NER, and how hard it was to create domain-specific chatbots even with amazing frameworks like RASA. And it does not matter what you do. You still used to get compromised UX for the end users. Companies will have an opportunity to refine their customer service using LLMs. UX is so much better with LLMs. Probably the best conversation humans had with the silicon chip.
- Corporate brain: Glean kind of product built for all the organization's Wiki and internal documents, except compared to Glean, it’s better since it can reason and generate better responses.
- Zero-ETL use case. I found this article by Bar Moses really interesting. As LLMs become more powerful, seeing how they disrupt data processes, massive ETL pipelines, and processes in place will be interesting. Also, this research paper is very interesting if you want to read it. There still need to be more questions regarding creating production-grade pipelines and the necessary measures to test them effectively.
- Data labeling and classification at scale. If you are interested, there is an interesting Jupyter Notebook from OpenAI on classification tasks through the model and comparing the results. Also, Cohere has an interesting endpoint for a similar use case.
- Specialized CoPilots: Drawing inspiration from GitHub Copilot, there is potential for creating specialized CoPilots for various professions, including healthcare workers, financial analysts, and more.
- Summarizing content. Summaries are good, although they did drop a lot of relevant information when we tried using them. There is substantial room for enhancement in this area.
- Capitalizing on untapped, unstructured data: Many organizations possess vast datasets but are still determining how best to utilize them. The advanced embedding techniques that LLMs offer can assist these organizations in clustering, reasoning, and making nuanced use of their data. Techniques like RAG further enable them to operationalize this data for internal processes or end users.
- Boosting developer or employee productivity: LLMs can undeniably enhance developer efficiency, often called the ‘10X’ effect. However, organizations must proceed cautiously, taking lessons from incidents like the one with Samsung. This is where internal LLMs deployed within an organization’s Virtual Private Cloud (VPC) could offer a valuable safeguard. It presents a compelling case for enterprises to deploy their own LLMs. This topic remains a lively debate, and seeing the industry's direction will be intriguing.
The next article will explore building long-term user action memory and routing techniques for information retrieval. Hang on! I think I’ll update this bit later, depending on which topic I manage to publish first.
References¶
- In-Context Retrieval-Augmented Language Models
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- Text and Code Embeddings by Contrastive Pre-Training
- An Example-Driven Tabular Transformer by Leveraging Large Language Models
- Large Language Models can self improve
- PinnerSage: Multi-Modal User Embedding Framework for Recommendations at Pinterest
- Language Models as Recommender Systems: Evaluations and Limitations
Subscribe
Honest takes on AI, startups, and digital health—delivered to your inbox.
Your privacy is paramount. Expect content once or twice a month. Unsubscribe anytime if you don't like it.
Get Email Updates