
Delayed task queue: How Vincere evolved from one Lambda to a persistent queue¶
Vincere uses incentives. behavioral nudges and evidence-based interventions for healthy behaviors and making healthy choices. This requires us to track multiple events for users and nudging them through reminders/notifications towards better health
Our Background and Requirements¶
Vincere allows health coaches to create a participant monitoring Campaign. A health coach can define the following things in a Campaign
-
Bio-marker feedback. e.g, CO(Carbon Monoxide) monitoring for smokers through a breathalyzer device using a mobile app. We are capable of doing other bio-marker feedback as well
-
Define a Campaign to run for multiple days/months that can track multiple events just like on a calendar, e.g, breath test at a specific time or on a specific day, other bio-marker feedback, payment event where participants will be getting paid at a certain time or day, or participant/coach appointments for video/audio calls
-
Define certain incentives/rewards criteria for achieving a certain goal in the defined testing window or making it to the appointments
-
Define notifications criteria or reminders. These notifications are very personalized notifications and could be configured to go out at different intervals looking at the user information
Since we have to track different time-based testing windows and sending notifications at certain defined times we could not do this in a synchronous web request. We had some design discussions internally within the team about doing all of this on the client-side (front-end). We soon realized it will be hard to schedule something on the client-side if the app is not running in the background and another problem was besides doing push notifications we also deal with email/SMS notifications both for app participants and the health coaches, and events like payment processing where users will be getting paid. We decided to write a cronjob.
Like many initial designs, our goal was to get something out there fast and working, to gather feedback from our users, and optimize later
First Iteration of Background Jobs¶
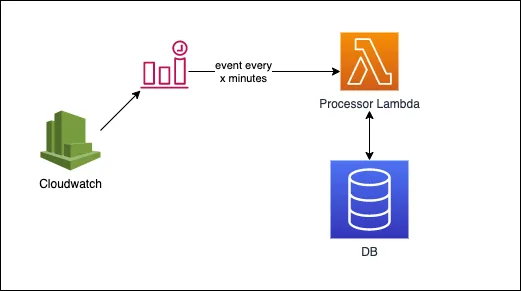
The first iteration worked like this
-
We had one Lambda function. that was triggered every 1 minute through a scheduled cloud-watch event
-
It will scan all the rows in the Postgres Database and based on UTC timestamp it will decide to take action and perform different kinds of mutations in the database
Pros¶
- It was really easy to develop a Lambda function, where cron scheduling is handled by CloudWatch triggered events, which makes sure there is one execution of lambda function to avoid duplicate processing and we got something functional out there faster
Cons¶
- It was a single point of failure and not fault-tolerant. And it did fail multiple times in later stages when there was an error related to a single event processing e.g, missing or malformed data and it had a cascading effect on the processing of all the events in that scheduled window. We re-factored the code but catching these errors in a fault-tolerant manner was hard. Also making sure one error does not cause all events to fail was hard
- One Lambda cannot scale horizontally. As we were not doing any workload distribution or a fan-out. As the events were growing it used to take one Lambda function much longer to process them all and most of the notifications were delayed. We vertically scaled the Lambda by increasing the memory/CPU and time limit within the AWS console. This gave us some runway to optimize later
Second Iteration of Background Jobs¶
We decided to use a background job queue to process different events and handle the scheduling piece of them using a delayed task queue. We had the following requirements from a job queue
- Tracking job state and stats e.g, the status of the job, the run duration, etc.
- Automatic recovery if a worker crashes e.g retries with exponential backoffs and tracking them
- Pushed based PUB/SUB design instead of continuous polling
- Scheduled and delayed jobs
- Low over-head over creating queue topics or multiple types of queues
- Concurrency and horizontally scaling the load among distributed workers across different CPUs
Our stack was running on AWS. So we decided to explore SQS as a distributed job queue for the fan-out and reliability. But we soon realized long scheduling jobs in the future are hard to achieve with SQS with an upper limit of 12 hours visibility timeout (time after which message is visible for processing). For long-scheduled tasks, a message needs to be picked up and delayed again depending on how long in the future a job is scheduled. This makes the design very complex when you have a job that has to run in the future e.g, an incentive payment event that has to run after a month
Our team was already using Redis for caching purposes. We decided to use Redis as a delayed task execution queue. Redis supports delayed tasks with reasonable timing precision with minimal resource waste when idle. We explored a couple of stable packages for this use-case. e.g, Sidekiq in Rails, Celery with Redis in Python, and Bull in NodeJs. As most of our tech stack was in NodeJs we decided to go with the bull for running long-scheduled tasks and it fulfilled most of our requirements at the time
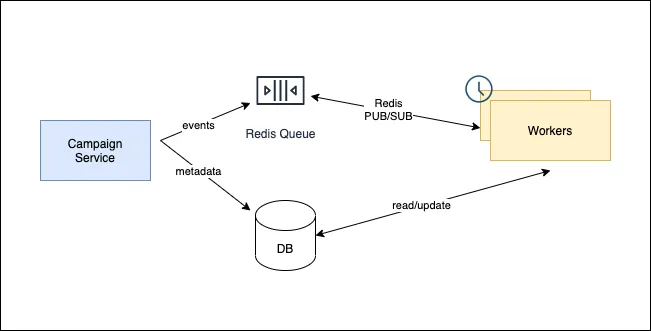
The second iteration worked like this
- At the time of Campaign creation, we submit all the scheduled events to Redis through bull package with a timestamp it is supposed to run on, with high-level metadata about Campaign starting and ending date in the database
- A NodeJs process will process a job at some point in time when it is ready. We can add re-try logic in-case of failures and this was all handled by bull queue manager
- There could be multiple job processors running in multiple Node Docker containers for horizontal scalability. Bull aims for “at least once strategy”. But in some scenarios, a job could be retired multiple times. Making processes atomic is your job. We achieved this through PostgreSQL, which is discussed later in the article
Pros¶
- We were able to achieve horizontal scalability, every event was processed in a separate process/worker and had no impact on other events in-case of failure
- With BULL, there was built-in retry logic with an exponential backoff which helps to prevent sporadic errors like network issues
- Pushed based PUB/SUB design with delayed events were processed with reasonable timing precision
- For monitoring jobs, we were able to use an open-source UI which helped us a lot to track job states
Cons¶
- Redis is not backed by disk. It works really well for the immediate jobs where you need high throughput, to keep jobs that have to run in the future consumes lots of memory and it is costly
- The way we were using Redis for long-scheduled tasks was not ideal. We used to submit all the events in Redis at the time of Campaign creation and individual job state mutations were not being tracked in the SQL database in an immutable or append-only manner. Since every historical state mutation at any point in time was not being tracked in a centralized place it was really hard for us to re-try or audit all the events processed or failed. At one point our EC2 server EBS volumes ran out of disk space due to an issue where log files were not being truncated. All the Redis jobs started failing because they couldn’t write the log statements to disk and exhausted all the re-try attempts even with exponential backoff. Since not all the events were tracked it was really hard for us to re-try a particular event after fixing the issue
- As the backend at Vincere was maturing we started creating multiple micro-services. Most of them had to interact with a job queue for delayed or immediate processing. We were very tightly coupled with Redis and Bull. There wasn’t one documented interface to enqueue jobs. All the developers had to get familiar with Bull API. And if we were to change our queue e.g, move to SQS or Kafka in the future it would be impossible to change application code due to tight coupling
Third Iteration of Background Jobs¶
After a couple of iterations, we decided to write our own Job Queue utilizing PostgresSQL. We called it Programma. You might be wondering why "reinvent the wheel". Following were the main reasons we took this path
- Our use-case was to track these jobs in one place for simplicity, like SQL/NoSQL store without too much effort in a simple schema model. We attempt to track job states in Postgres through a simple interface. We choose Postgres due to its SKIP LOCK feature that is very suitable for building a queue backed by Postgres
- The goal of Programma is to expose a very flexible and simple API. Where client could nudge the job processing lifecycle by calling utility methods without us dictating the specific lifecycle of a job
- Programma ensures a job is delivered and claimed by the processor with retryAfterSeconds logic until job status is changed. This parameter is customizable and you can use it for exponential backoff logic as well by changing the retryAfterSeconds. Received messages that are not changed to either Processing, Completed, or FAILED state will appear again after retryAfterSecond timeout
- Programma exposes Promise-based API and written in typescript which helps us a lot since most of our stack is in NodeJS and Typescript helps us to create self-documenting job interfaces
The third iteration and current iteration works like this
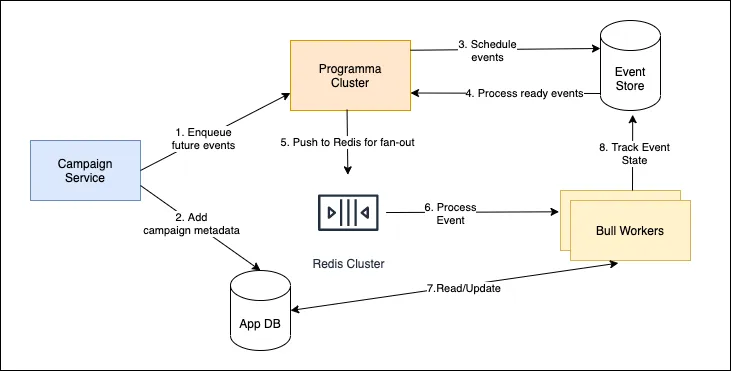
- At the time of Campaign creation, we enqueue all the jobs using Programma API and add high-level campaign metadata in our application database
- Programma creates entries of jobs in the event-store(Postgres)
- Programma processor keeps polling database at a certain interval to see if there are any jobs that ready to be processed. We run multiple job poolers on different servers/containers for workload distribution. We can customize the pooling interval and max jobs per interval. This is where the Postgres SKIP LOCK feature comes really handy to skip the rows that are already claimed and avoid double processing
- Once a job is ready to be processed we change the job status to processing. Programma does not implement any job worker logic. That's why we fan-out all the ready jobs to Redis Queue with Bull for processing
- Once a job is processed by the Bull Worker we update the job status in the event-store using Programma API. Re-try logic is handled by the Bull queue manager
Our application code and different microservices enqueue the jobs using the following API
interface IJobConfig {
data: {}
attributes?: {}
runAfterSeconds?: number
runAfterDate?: string | Date
retryAfterSeconds?: number | null
}
interface IProgramma {
addJob(topicName: string, job: IJobConfig): Promise<string | null>
}
const job = await programma.addJob('sendEmail', {
data: { email: 'test@xyz.com' },
runAfterDate: '2021-11-30T06:41:26.536Z', // run job next year
})
Job Processing microservices keep pooling the jobs like in the following example
interface IProgramma {
receiveJobs(config: IReceiveMessageConfig, handler: IHandlerCallback): void
}
programma.receiveJobs({ topicName: 'sendEmail' }, async (job: IReceiveJob) => {
// use bull to fan-out the jobs to different
// reliable sandboxed workers with retry logic
await bullRedisQueue.add(
{ id: job.id, data: job.data, attributes: job.data },
{ retries: 3, backoff: 20000, timeout: 15000 }
)
// move job to processing, after submitting it.
// the status will be changed to processing and Redis queue will handle it
// if a job is not moved to different state
// it will be retired after retryAfterSecond period
await programma.moveJobToProcessing(job.id)
})
Each job will be processed by an individual Bull Worker which is a separate Node process. Once a job is processed successfully, we change job status and track in DB through Programma API
bullEmailRedisQueue.process(async (job, done) => {
try {
// send email
await programma.moveJobToDone(jod.data.id)
return Promise.resolve()
} catch (e) {
return Promise.reject()
}
}
// job failed after all the back-off retries
// we can track that in SQL through programma API
bullRedisQueue.on('failed', (id, error) => {
const job = await bullRedisQueue.getJob(id)
await programma.moveJobToFailed(jod.data.id)
// also can track error in SQL
await programma.setAttributes(job.id, { error: error })
})
Pros¶
- Code abstraction that’s easy for developers to work with and different micro-services use simple API to enqueue background jobs
- Delayed tasks that have to run in the future do not consume too much memory
- Everything is tracked in one centralized event-store which is reliable i.e, backed by the disk, and for throughput, we utilize Redis PUB/SUB to fan-out jobs to different processors
- We can achieve horizontal scalability by running job polling logic on different CPUs/containers. Thanks to Postgres SKIP LOCK which help us achieve this
Cons¶
Some of these might not be cons. But we will discuss trade-offs and future scalability problems
- Since every job regardless if it has to run immediately or in the future is tracked in event-store it consumes lots of space and the index size grows too. We plan to solve this in the future by running a configurable job archival process
- One SQL Database won’t be able to handle all the load. We plan to create multiple Programma clusters and shard tasks by Organization Id or something more efficient and route them to different clusters. Since Programma handles Job Table schema creation on the fly if it does not exist, we can run multiple local Postgres databases per programma cluster and scale-out. We are very inspired by the Pinterest implementation of pinlater and how it can scale out with MySQL based queue implementation
- Pooling based design instead of PUB/SUB wastes some CPU resources where you are continuously pooling even when no jobs are available to be processed in a particular interval. This is one of the tradeoffs we have to make for simplicity and reliability
Avoiding duplicate processing of Jobs¶
As we process payment events, where our users get paid through different payment gateways. We cannot take risk of double processing the event. Even with Postgres SKIP LOCK and Bull it’s hard to run into a scenario where a job is processed twice, but the situation could arise when the queue is stalled. For such jobs, we use distributed locks with Redis Redlock. You can read this topic here regarding the distributed lock implementation
try {
// try to acquire lock
redlock.lock(job.id, 5000) // acquire lock for 5 seconds
// process payment
} catch (e) {
// failed to acquire job. try next time
}
Next Steps¶
- Most of our background job workflows are evolving into a DAG (Directed Acyclic Graph). We plan to model the parent-child relationship of jobs in the future for maintainability and having better visibility over workflows
- Creating a better API for queue metrics and measuring queue depth. If a job is not processed in a specific interval maybe set up some alarms etc.
- Creating a better archival process for the processed job for event-store maintainability
References¶
- Bull Queue Documentation
- Understanding SELECT ... SKIP LOCKED in PostgreSQL
- Redis Distributed Locks
- Qmessage: Handling Billions of Tasks Per Day
- Pinterest's Pinlater
- Building a Multi-Tenant Job Queue System with PostgreSQL
Subscribe
Honest takes on AI, startups, and digital health—delivered to your inbox.
Your privacy is paramount. Expect content once or twice a month. Unsubscribe anytime if you don't like it.
Get Email Updates